Top og bund i dansk politik
Dansk politik er meget mere end et valg mellem højre og venstre. En analyse af hvordan danske politikere har stemt i folketinget 2019-2020 viser, at kampen mellem 'toppen' og 'bunden', dvs. mellem et politisk establishment bestående af de store midterpartier, og et anti-establishment bestående af yderfløjspartierne, er næste lige så stor som kampen mellem højre- og venstrefløj.



Vi har for vane at opdele politik i højre- og venstrefløj. Den historiske årsag er oplysende: det var sådan medlemmerne af den franske nationalforsamling placerede sig efter den franske revolution i 1789. Dem til højre i salen var loyale over for konge og kirke, dem til venstre støttede revolutionen. På den måde undgik man de værste albuehug og slåskampe mens man skændtes om Frankrings fremtid.
Hvordan burde de danske medlemmer af folketinget sidde i dag, hvis vi ville minimere risikoen for den slags håndgemæng? Spurgt på en anden måde: hvordan placerer man danske politiker i et lokale så deres politiske uenighed afspejles bedst muligt af deres indbyrdes afstande på en to-dimensionel flade?
Der findes faktisk en simpel matematisk metode til at finde ud af det på. Den kaldes en 'principal component analyse' (pca), og bliver brugt flittigt i maskinlæring og til at lave undersøgende dataanalyse. Gevinsten ved at bruge en pca på folketingets afstemninger er, at vi kan se om de politiske partier vitterlig stemmer i forhold til det vil forestiller os som en højre- og venstrefløj i dansk politik. Vi vil med andre ord kunne svare på om det virkelig er rigtig, at Enhedslisten og Dansk Folkeparti er længst fra hinanden. Vi vil også kunne finde ud af, hvordan partierne grupperer sig i forhold til andre akser, hvor afstandene måske er lige så store. Da der jo er lige så mange politiske synspunkter i folketinget som der er folketingsmedlemmer, er pca'en en rigtig god måde til at reducere de mange uenigheder ned til de to eller tre mest betydningsfulde uenigheds-typer der kendetegner dansk politik. En analyse på tværs af årene vil desuden kunne vise, hvordan partierne har bevæget sig i forhold til hinanden i løbet af årene.
Vi starter med at se på det danske folketing anno 2020:

Der er ti danske partier og fire oversøiske. Og så er der fire (pr. 4. dec 5) mandater uden for folketingsgrupperne som udgør løsgængerne fra de Frie Grønne samt Simon Emil Ammitzbøll-Bille. Alle data finder vi via den frit tilgængelige database på oda.ft.dk.
import sys
import pyodbc
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xml.etree.ElementTree as ET
from collections import Counter
from sklearn.decomposition import PCA
from adjustText import adjust_text
import seaborn as sns
sns.set_style('white')
sns.set_context('notebook')
plt.rcParams["font.family"] = "sans-serif"
PLOTS_DIR = 'images'
%matplotlib inline
Vi starter med at kalde SQL serveren og skrive en søgning til oda-databasen, hvorefter resultatet importeres til en pandas dataframe. Den periode vi er interesseret i er perioden 2019-2020 som har id = 151.
periodid = 151
conn = pyodbc.connect('Driver={SQL Server};'
'Server=HUM1006903\SQLEXPRESS;'
'Database=oda_20201103;'
#'Database=oda;'
'Trusted_Connection=yes;')
cursor = conn.cursor()
sql_query = pd.read_sql_query('SELECT \
oda.dbo.Afstemning.id AS afstemning, \
oda.dbo.Sag.periodeid, \
oda.dbo.Periode.titel AS periode, \
oda.dbo.Sag.titel AS titel, \
oda.dbo.Sag.resume, \
oda.dbo.Afstemning.konklusion, \
oda.dbo.Sagstrin.dato, \
oda.dbo.Stemme.typeid AS stemme, \
oda.dbo.Aktør.fornavn, \
oda.dbo.Aktør.efternavn, \
oda.dbo.Aktør.biografi \
FROM oda.dbo.Afstemning \
JOIN oda.dbo.Stemme ON oda.dbo.Afstemning.id = oda.dbo.Stemme.afstemningid \
JOIN oda.dbo.Aktør ON oda.dbo.Aktør.id = oda.dbo.Stemme.aktørid \
JOIN oda.dbo.Sagstrin ON oda.dbo.Sagstrin.id = oda.dbo.Afstemning.sagstrinid \
JOIN oda.dbo.Sag ON oda.dbo.Sag.id = oda.dbo.Sagstrin.sagid \
JOIN oda.dbo.Periode ON oda.dbo.Sag.periodeid = oda.dbo.Periode.id \
WHERE oda.dbo.Sag.periodeid='+str(periodid)+';', conn)
sql_query.head()
print(len(sql_query.afstemning.unique()))
print(len(sql_query))
Som man kan se, er der kun 323 afstemninger og knap 58.000 rækker i dataframen. Coronakrisen i 2020 betød at afstemninger mellem 28. maj 2020 og slut oktober blev foretaget ved håndsoprækkelse og derfor ikke er inkluderet i databasen.
I det følgende skal data renses og formatteres. Vi kan se, at tabellen ikke indeholder nogen kolonne, der angiver hvilket parti folketingsmedlemmerne tilhører. Det haves ikke i databasen. Eneste sted jeg kan se, at man kan finde et folketingsmedlems partitilknytning i data er i "biografi"-kolonnen, som består af en masse XML tags. For at ekstrahere partinavnet, der er placeret mellem tagsene "party", bruger jeg bibliotekten xml.etree:
party = []
for bio_string in sql_query['biografi'].values:
try:
root = ET.fromstring(bio_string)
for child in root.findall("./party"):
party.append(child.text)
except Exception as e:
party.append(None)
continue
sql_query['party'] = party
#sql_query.party.unique()
Næste skridt i rensningen af data består i at omkode de enkelte stemmer så deres numeriske værdi er normaliseret og kan bruges i analysen. Folketingets database har kodet dem sådan at et 1-tal betyder en stemme FOR, et 2-tal betyder IMOD, et 3-tal betyder FRAVÆR, og et 4-tal betyder "Hverken for eller imod". I stedet koder jeg dem sådan at 1 betyder FOR, -1 betyder "IMOD", og 0 betyder "hverken for eller imod. Desuden samler jeg for- og efternavn og beholder kun de kolonner, vi har brug for:
sql_query['navn'] = sql_query[['fornavn', 'efternavn']].agg(' '.join, axis=1)
df = sql_query[['afstemning', 'titel', 'resume', 'konklusion', 'navn', 'party', 'stemme']]
df['stemme'].replace(to_replace=2, value=-1, inplace=True)
df['stemme'].replace(to_replace=4, value=0, inplace=True)
df.tail()
Lad os lige se hvor mange stemmer der er i hver kategori:
Counter(df.stemme)
Desværre viser det sig at der er rigtig mange fravær i folketinget (mange 3-taller), og manglende stemmer gør det vanskeligt at foretage en ordentlig PCA, fordi de gængs PCA-algoritmer ikke kan klare NaNs. Da der er mødepligt i folketinget, og alle folketingsmedlemmer SKAL stemme ved alle afstemninger, er det jo en mærkelig sag. Men det viser sig, at folketingets partier benytter sig af såkaldte 'clearingsaftaler', som er private aftaler mellem de forskellige folketingsgrupper. Aftalerne sikrer, at et antal folketingsmedlemmer fra hver partigruppe kan få 'fri' fra afstemningerne i folketingssalen, uden at der derved rokkes ved, hvilke partier som har flertal i Folketinget, eller ved, at der skal være mindst 90 medlemmer til stede, for at Folketinget er beslutningsdygtigt. Clearingaftalerne giver dermed mulighed for, at de politiske aktiviteter ikke går i stå, selv om der er møde og afstemninger i salen. Aftalerne giver plads til, at medlemmerne kan deltage i f.eks. politiske møder eller deltage i andre aktiviteter uden for Christiansborg, uden at afstemningerne i folketingssalen af den grund får et utilsigtet udfald.
I praksis indgås aftalerne typisk ved, at partigrupperne parvist aftaler for en hel folketingssamling, hvor mange medlemmer hver partigruppe kan 'cleare' hos hinanden - dvs. give lov til at blive væk fra afstemningerne, fordi den politiske modpart også beder et antal medlemmer blive væk. Når et medlem er clearet, stemmer medlemmet ikke i salen den pågældende dag. Hvordan clearingerne fordeles på medlemmer i partigrupperne kan veksle fra dag til dag, alt efter hvem der har behov for at være fri for at deltage i afstemningerne i salen. Det er typisk gruppesekretæren i den enkelte folketingsgruppe, som koordinerer fordelingen af clearingerne og sikrer, at man kan stille med det aftalte antal medlemmer ved eventuelle afstemninger. Det er også typisk gruppesekretæren, som tager kontakt til sin modpart i de andre partigrupper, hvis man pludselig har mandefald på grund af f.eks. sygdom eller lignende, og aftaler de nødvendige yderligere clearinger for en relevant periode. Det typiske mønster for clearingaftalerne er, at regeringspartierne clearer medlemmer med deres umiddelbare modpart. Dermed sikrer man lettest, at den politiske balance er bevaret på trods af clearingerne.
Efter en samtale med partisekretær Annette Lind (S), som i nuværende folketingssamling en den der sammen med Erling Bonnesen (V) koordinerer clearningsaftalerne for alle partierne, forstå jeg at hvis en person bliver clearet, så vil den person ALTID stemme ihht. partilinjen. Det vil sige at jeg kan skrive en funktion, der erstatter alle fravær med typetallet ("mode") for partiet for den givne afstemning. I tilfælde af at fravær er den hyppigste adfærd, vælger jeg i stedet den anden mest hyppige stemmetype. Og hvis alle medlemmer af et parti har været fraværende ved en afstemning (hvilket hyppigt sker for de grønlandske og færøske stemmer), sætter jeg dem til at være hverken for eller imod, dvs. til 0. Hvis et folketingsmedlem er "Uden for folketingsgrupperne", ændrer jeg FRAVÆR til "Hverken for eller imod" da jeg ikke kunne få bekræftet om løsgængerne også benytter sig af clearningsaftaler.
def get_most_frequent_vote(afstemning, party):
df_ap = df[(df.afstemning == afstemning) & (df.party == party)]
party_votes = df_ap.stemme.values
cnt = Counter(party_votes)
mostfrequent_vote = cnt.most_common()[0][0]
if mostfrequent_vote == 3:
try:
mostfrequent_vote = cnt.most_common()[1][0] # set the second most frequent vote as the most frequent one.
except: # if all members of the party have been absent
mostfrequent_vote = 0 # set their most frequent vote to be "abstain"
return mostfrequent_vote
for i, row in df.iterrows():
if row['stemme'] == 3:
if row['party'] == 'Uden for folketingsgrupperne':
df.at[i,'stemme'] = 0
else:
ifor_val = get_most_frequent_vote(row['afstemning'], row['party'])
df.at[i,'stemme'] = ifor_val
Counter(df.stemme)
For at få data i det rigtige format, bliver vi dernæst nød til at reorganisere tabellen således at rækkerne viser de enkelte folketingsmedlemmer, søjlerne de enkelte afstemninger, og selve cellerne indeholder så stemmerne. Vi kan bruge pivot-funtionen i python:
dp = df.pivot_table(index = ['navn', 'party'], columns=['afstemning'], values=['stemme'])
dp.dropna(inplace=True)
dp.columns = [col[1] for col in dp.columns] # get rid of the extra multicolumn "vote"
dp = dp.reset_index(level=['navn', 'party']) # make the multiindex [name, party] into two columns
dp.head()
Dernæst giver vi partierne en farve, så vi kan kende forskel på dem på det resulterende plot:
# compute the color that each MP should be, based on their party. color codes are taken from https://www.dr.dk/om-dr/designmanager/temapakker/folketingsvalg-2019
color_dict = {
'Enhedslisten' : '#E6801A',
'Socialistisk Folkeparti' : '#E07EA8',
'Sambandsflokkurin' : '#41b6c4',
'Javnaðarflokkurin' : '#67001f',
'Socialdemokratiet' : '#A82721',
'Siumut' : '#ef3b2c',
'Radikale Venstre' : '#733280',
'Inuit Ataqatigiit' : '#980043',
'Det Konservative Folkeparti' : '#96B226',
'Liberal Alliance' : '#3FB2BE',
'Venstre' : '#254264',
'Dansk Folkeparti': '#EAC73E',
'Uden for folketingsgrupperne' : '#737373',
'nan' : 'black',
'Alternativet' : '#2B8738',
'Nye Borgerlige' : '#127B7F',
'Kristendemokraterne' : '#8B8474',
'Klaus Riskær Pedersen' : '#6C8BB8',
'Stram Kurs' : '#998F4D',
'Nunatta Qitornai' : '#c51b8a',
'Tjóðveldi' : '#a6d96a'
}
def party_color(x):
return color_dict.get(str(x),'black')
colors = [party_color(x) for x in dp['party']]
De originale data har lige så mange dimensioner som folketingsmedlemmer, men pca'en reducerer dem ned til tre eller endda kun to dimensioner. De to/tre dimensioner er så til gengæld dem, der viser størst varians i folketingsmedlemmernes stemmeadfærd, og kan derfor bruges som indikatorer for hvor meget folketingsmedlemmerne er uenige med hinanden. Dimensionerne er desuden ortogonale på hinanden, hvilket betyder at de er uafhængige af hinanden. Enhver korrelation mellem afstemningerne transformeres således til linæere ukorrelerede variable der kaldes 'komponenter'. PCA er altså en "usuperviseret" metode, der beregnet afstanden mellem partierne som en kompleks blanding af, hvordan der blev stemt i de 323 afstemninger der blev registreret i folketingssamlingen 2019-2020.
For at dimensions-reduktionen kan give et nogenlunde retvisende billede af forskellene er det dog vigtigt at de 2-3 principale komponenter fanger størstedelen af variansen i data. Forneden vælger vi antallet af komponenter til at være 3, og kalder den første komponent for xvector, den anden komponent for yvector, og den tredje zvector.
num_folketingsmedlemmer = len(dp)
num_bills = len(dp.columns)-2
bills = dp.columns[2:num_bills+2]
dat = dp.iloc[:,2:num_bills+2]
pca = PCA(n_components=3)
pca.fit(dat)
xvector = pca.components_[0]
yvector = pca.components_[1]
zvector = pca.components_[2]
xs = pca.transform(dat)[:,0]
ys = pca.transform(dat)[:,1]
zs = pca.transform(dat)[:,2]
pca.explained_variance_, pca.explained_variance_ratio_
Som det kan ses fanger den første komponent 44,4 procent af variansen i data. Det er ikke så meget som håbet (i de tidligere folketingsår kommer den typisk op på 60-70%), men skyldes nok det specielle Corona-år vi har haft. Vi må leve med det, og kan nu plotte resultatet for de to første komponenter:
fig, ax = plt.subplots()
ix_high = np.argsort(xvector)[-5:] # returns an array of sorted indexes of the components
ix_low = np.argsort(xvector)[:5]
iy_high = np.argsort(yvector)[-5:] # returns an array of sorted indexes of the components
iy_low = np.argsort(yvector)[:5]
ix_highest_and_lowest_comps = np.append(ix_high, ix_low)
iy_highest_and_lowest_comps = np.append(iy_high, iy_low)
def get_arr_index_colors(color):
# returns an array of indexes in the colors array corresponding to a certain party with color "color"
col_mask = np.where(np.array(colors) == color,True,False)
col_index = np.arange(0, len(colors))[col_mask]
return col_index
for color in np.unique(colors):
ix_color = get_arr_index_colors(color)
ax.scatter(xs[ix_color], ys[ix_color], c = color, label = list(color_dict.keys())[list(color_dict.values()).index(color)])
for i in ix_color:
ax.annotate(dp.iloc[i]['navn'], (xs[i], ys[i]), fontsize=2)
for i in ix_highest_and_lowest_comps:
# arrows project features as vectors onto PC axes
plt.arrow(0, 0, xvector[i]*max(xs)*2, yvector[i]*max(ys)*2,
color='grey', width=0.0005, head_width=0.005)
texts = [plt.text(xvector[i]*max(xs)*2.2, yvector[i]*max(ys)*2.2,
list(dat.columns.values)[i], color='black', fontsize=3)]
for i in iy_highest_and_lowest_comps:
# arrows project features as vectors onto PC axes
plt.arrow(0, 0, xvector[i]*max(xs)*2, yvector[i]*max(ys)*2,
color='grey', width=0.0005, head_width=0.005)
plt.text(xvector[i]*max(xs)*2.2, yvector[i]*max(ys)*2.2,
list(dat.columns.values)[i], color='black', fontsize=3)
plt.scatter(0,0, color='white', s=4, zorder=20)
adjust_text(texts)
lgd = ax.legend(title=str(num_bills)+' afstemninger', prop={'size': 10}, bbox_to_anchor=(1.05, 1))
ax.set_title('Folketingsperiode ' + period_txt, fontsize=14)
# invert the x-axis so that the "left wing" goes to the left and the "right wing" to the right. First grab a reference to the current axes and then set the xlimits to be the reverse of the current xlimits
ax = plt.gca()
ax.set_xlim(ax.get_xlim()[::-1]) # vi vender akserne om, så det matcher med det visuelle udtryk om at venstrefløjen er på venstre side og højrefløjen på højre side.
ax.set_ylim(ax.get_ylim()[::-1])
#ax.set_xlim([25,-15])
#ax.set_ylim([12.5,-12.5])
#plt.tight_layout()
# Remember: save as pdf and transparent=True for Adobe Illustrator
if not os.path.exists(PLOTS_DIR):
os.makedirs(PLOTS_DIR)
plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'.png'), bbox_extra_artists=(lgd,), bbox_inches='tight', transparent=True, dpi=800)
plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'.pdf'), bbox_extra_artists=(lgd,), bbox_inches='tight', transparent=True, dpi=800)
plt.close()
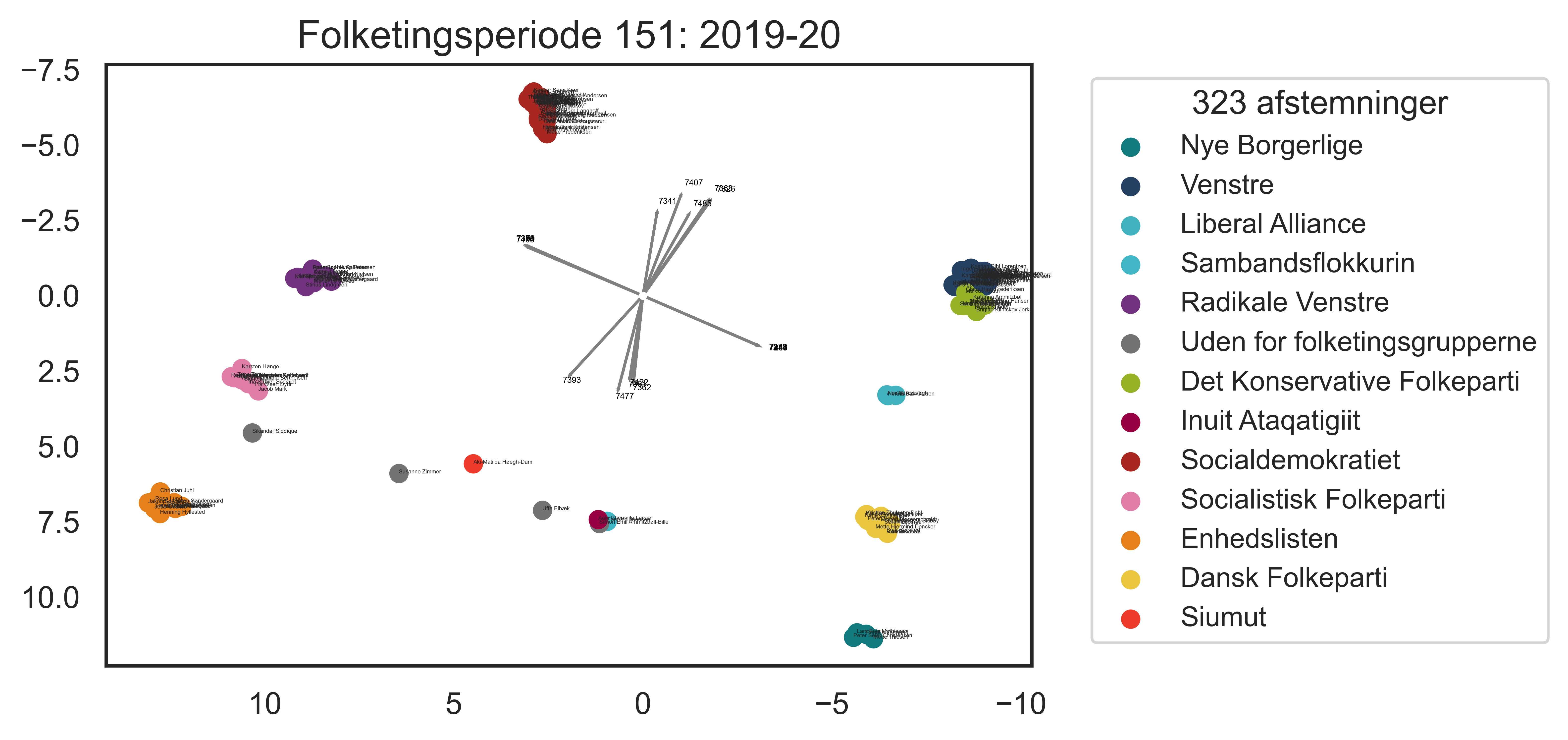
x-aksen giver et ganske godt billede af hvad vi normalt forestiller os som den ideologiske højre-venstre akse i dansk politik. Enhedslisten ligger yderst til venstre, og Dansk Folkeparti ligger yderst til højre (i hvert fald i årene før folketingsvalget i efteråret 2018), og i midten øverst ligger Socialdemokratiet. Der er dog et par overraskelser. De Radikale venstre ligger klart til venstre for Socialdemokratiet, ja faktisk tættere på SF end på S. De mest 'højreorienterede' partier i dansk politik er hverken Dansk Folkeparti eller de Nye Borgerlige. Det er Venstre og Det Konservative Folkeparti, to partier der i øvrigt er stort set uskelnelige i deres stemmerafgivelser. De oversøiske mandater roder rundt i midten, hvilket primært er en konsekvens af at de ofte afholder sig fra at stemme eller stemmer 'hverken for eller imod'.
Pilene, som udspringer fra (0,0) er de fem største eigenvektorer for covariansmatricen for hver komponent, og repræsenterer kernen i en pca: de viser retningen på de afstemninger som er væsentligst for de to første komponenter. F.eks. peger en vektor i retning af kl. 7:30, og den fortæller os, at afstemning 7393 (Forslag til lov om dyrevelfærd) var een af de afstemninger, der adskildte de venstreorienterede og "bund"-partierne mest fra resten (forslaget blev forkastet. For stemte 41 - DF, RV, SF, EL og ALT, og imod stemte 62 - S, V, KF, NB og LA).
Lad os prøve at se lidt nærmere på denne første komponent i PCA-analysen, som altså projicerer ned på en akse de største forskelle mellem de danske politikere, og som står for circa 45 % af variansen i data. Vi starter med at plotte et heat map for at se, hvilke afstemninger der har haft størst og mindst betydning for denne spredning.
# da der er 323 afstemninger tilføjer vil et ekstra element så vi har 12x27 elementer,
# som vi så kan plotte ved at bruge matshow. Jeg har brugt en farvekode som angiver de
# afstemninger der er vigtige for højrefløjen med blå, og dem der er vigtige for
# venstrefløjen med rød.
b = np.append(bills, [0])
b = b.reshape(12,27)
w = np.append(xvector, [0])
w = w.reshape(12,27)
fig, ax = plt.subplots(figsize=(12,8))
mesh = ax.matshow(w, cmap='seismic')
for (i, j), z in np.ndenumerate(b):
ax.text(j, i, '{}'.format(z), ha='center', va='center', fontsize=4, bbox=dict(boxstyle='round', facecolor='white', edgecolor='0.3'))
plt.colorbar(mesh, ax=ax, fraction=0.02, pad=0.04) # arguments shrink the colorbar
# Remember: save as pdf and transparent=True for Adobe Illustrator
if not os.path.exists(PLOTS_DIR):
os.makedirs(PLOTS_DIR)
plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'_heatmap_1.png'), transparent=True, dpi=300)
# plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'_heatmap_1.pdf'), transparent=True, dpi=800)
plt.close()

Plottet viser i rødt de afstemninger som (hvis vedtaget) har rykket Danmark mod venstre, og i blåt de afstemninger som (hvis vedtaget) har rykket Danmark mod højre. Det er tydeligt at der er stor forskel på, hvor meget en bestemt afstemning betyder for denne første komponent. Vi kan prøve at printe resumeet for de fem vigtigste afstemninger i hver retning (højre og venstre), og se om de også repræsenterer politiske temaer, som vi typisk forbinder med en højre- og venstrefløj:
print('Her de mest polariserende afstemninger som de røde (dvs. venstrefløjen + S) stemte for og vandt:\n')
for lov in bills[ix_high]:
print('afstemnings-id', lov)
pprint.pprint(df[df.afstemning == lov].titel.unique()[0])
pprint.pprint(df[df.afstemning == lov].konklusion.unique()[0])
pprint.pprint(df[df.afstemning == lov].resume.unique()[0])
print('\n\n')
print('Her de mest polariserende afstemninger som de blå (dvs. højrefløjen) stemte for og tabte:\n')
for lov in bills[ix_low]:
print('afstemnings-id', lov)
pprint.pprint(df[df.afstemning == lov].titel.unique()[0])
pprint.pprint(df[df.afstemning == lov].konklusion.unique()[0])
pprint.pprint(df[df.afstemning == lov].resume.unique()[0])
print('\n\n')
Så hvad viser dette? Højre-venstrefløjs-aksen handler om emner som ordentlige arbejdsforhold hos chauffører og vognmænd, om børnebidrag til enlige forsørgere, om afskaffelse af opholdskrav for ret til dagpenge, samt finanslovsting. Altså ting man kunne forvente at der var uenighed om mellem de to fløje, og som venstrefløjen + S fik igennem fordi de har flertal.
Hvad så med y-aksen, altså bunden vs. toppen i figuren? Her skal vi kigge på den anden komponent, og vi starter igen med at tegne et heatmap:
# nu det samme for anden component:
w = np.append(yvector, [0])
w = w.reshape(12,27)
fig, ax = plt.subplots(figsize=(12,8))
mesh = ax.matshow(w, cmap='PiYG')
for (i, j), z in np.ndenumerate(b):
ax.text(j, i, '{}'.format(z), ha='center', va='center', fontsize=4, bbox=dict(boxstyle='round', facecolor='white', edgecolor='0.3'))
plt.colorbar(mesh, ax=ax, fraction=0.02, pad=0.04)
# Remember: save as pdf and transparent=True for Adobe Illustrator
if not os.path.exists(PLOTS_DIR):
os.makedirs(PLOTS_DIR)
plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'_heatmap_2.png'), transparent=True, dpi=300)
# plt.savefig(os.path.join(PLOTS_DIR, 'ft'+str(periodid)+'_heatmap_2.pdf'), transparent=True, dpi=800)
plt.close()

Vi printer igen de fem vigtigste afsteninger i hver sin retning (altså op og ned):
iyhigh = np.argsort(yvector)[-5:] # returns an array of sorted indexes of the components
print('Her de mest polariserende afstemninger som de grønne (dvs. bunden) stemte for og tabte:\n')
for lov in bills[iyhigh]:
print('afstemnings-id', lov)
pprint.pprint(df[df.afstemning == lov].titel.unique()[0])
pprint.pprint(df[df.afstemning == lov].konklusion.unique()[0])
pprint.pprint(df[df.afstemning == lov].resume.unique()[0])
print('\n\n')
iylow = np.argsort(yvector)[:5]
print('Her de mest polariserende afstemninger som de lilla (dvs. toppen) stemte for og vandt:\n')
for lov in bills[iylow]:
print('afstemnings-id', lov)
pprint.pprint(df[df.afstemning == lov].titel.unique()[0])
pprint.pprint(df[df.afstemning == lov].konklusion.unique()[0])
pprint.pprint(df[df.afstemning == lov].resume.unique()[0])
print('\n\n')
Hvad viser dette? De mest polariserende afstemninger mellem top og bund handler om ting som offentlighedloven (bunden vil have den ændret, toppen ikke vil), mere dyrevelfærd (toppen vil ikke), afskaffelse af EU-privilegier (toppen vil ikke), ligeberettigelse til social pension (toppen vil ikke), fjernelse af politikeres frynsegoder (toppen vil ikke), og om imødekommelse af borgerforslag (toppen vil ikke). Blandt de emner som blev gennemført, men bunden stemte imod er nye regler for tvangsanbringelser, indvandrere, og diverse økonomiske regler (DF hhv EL er dog typisk langt fra hinanden i disse sager), og igen en modstand mod at udskyde ændring af offentlighedloven.
Alt i alt kan man måske sige at bund versus top i Dansk politik handler om dem der vil fjerne privilegier fra et bestemt 'establishment', og dem der vil beholde privilegierne. Der er dog tale om forskellige typer af 'establishment'. Nogle gange er det den politiske elite vs. resten, nogle gange er det EU vs. resten af verden, nogle gange er det mennesker vs. dyr, og nogle gange er det de rige vs. de ikke-så-rige. Den analyse passer også godt overens med Aarhus Universitets magtudredning "De Folkevalgte" fra 2004, hvori der står at "i modsætning til alle de andre partier ser 'midterpartierne' (sic - her menes S + V + KF) ikke et behov for at ændre magtforholdene i samfundet." (s. 246).
Måske kan man også med Larry Summers ord sige, at den næst-vigtigste skillelinje i dansk politik, efter højre-venstre opdelingen, er den der adskiller 'insiders' fra 'outsiders'. Outsiders er de frie mennesker, der råber op og siger hvad de har lyst til, men ikke bestemmer noget som helst. Insiders er dem der kun siger det, der er accepteret at sige som insider, og de lytter ikke til outsiderne (som de kalder ekstremister). Til gengæld får insiderne lov til at tage alle de vigtige beslutninger.